
INTRODUCTION
Communication among dumb and deaf people is done through visual and textual expressions. Gestural interaction is in the scope of secure and confidential interaction ( Rastgoo et al., 2020). Facial parts and hands are hugely powerful in expressing the opinions of humans in confidential interaction. Ordinary people must assume few syntactic meanings for expressions done by people of dumb and deaf communities ( Das et al., 2023). There exist different ways of expression or communication; however, the main mode of human interaction is speech, and if it can be slowed down, individuals need to utilize a tactile–kinesthetic mode of interaction in its place ( Mannan et al., 2022). As per the National Statistical Office survey report, the percentage of people with these disabilities in India has been 2.2% since December 2018. One of the highest adaptations for individuals with hearing and speech impairments is sign language. It is termed as a visual language ( Hameed et al., 2022). It has five fundamental variables: movement, hand shape, place, orientation, and elements like eyebrow movements and mouth shape. The research was conducted on voice generation with smart gloves that can offer a voice-to-sign language movement ( Elakkiya, 2021). Nevertheless, people who have no idea of sign language typically reject or undervalue public damage due to the lack of proper interactions between them ( Li et al., 2020). Therefore, this study devises a mechanism designed to remove the interaction gap and present all individuals with an equal and fair chance. It takes videos of the individual making hand gestures, passing, and processing them to the presented method that forecasts words ( Sharma and Kumar, 2021). The scheme then generated meaningful sentences of those words that can be transformed into the language chosen by the correspondent.
Long ago, numerous exciting studies existed for the detection of dynamic hand gestures for sign languages ( Pandey et al., 2023). The detection remains an inspiring problem despite efforts made in the domain in the past few years. The necessity for understanding multi-modal data like movement and hand gestures in the event of American Sign Language (ASL), whereas it creates a problem vaguer, is acute ( Aly and Aly, 2020). Additionally, a massive amount of words in sign language with comparable gestures having a few instances for all words makes the issue harder. Occasionally, the same signs from various viewpoints or various signers have various appearances ( Lee et al., 2021).
In this study, we propose an Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition (EBESO-TLSLR) technique for hearing-impaired persons. The presented EBESO-TLSLR technique aims to offer effective communication among hearing-impaired persons and normal people using deep learning (DL) models. In the EBESO-TLSLR technique, the SqueezeNet model is used for feature map generation. For recognition of sign language classes, the long short-term memory (LSTM) method can be used. Finally, the EBESO method is exploited for the optimal hyperparameter election of the LSTM approach. The simulation results of the EBESO-TLSLR method are validated on the sign language dataset.
RELATED STUDIES
Alnfiai (2023) presents an SSODL-ASLR method, expanded as shark smell optimization with DL-related automated sign language recognition, for speaking- and hearing-impaired people. The presented method focuses on the classification and recognition of sign language presented by deaf and dumb persons. In the initial phase, Mask RCNN approach can be used for sign language detection. Then, the SSO system with soft margin SVM method is employed for classifying sign languages. In Latif et al. (2021), the authors proposed an AI-related Arabic Sign Language (ArSL) Translator. This system can seize the image of the sign language effectuated by an individual who is deaf and offers real-time translation of hand gestures. New structures are devised to be mined from the imageries to be input to the four methods: regression, RF, RT, and bagging classifier.
In Latif et al. (2020), an ArSL detection structure with the design of the deep CNN (DCNN) was proposed. The goal is to aid persons with hearing difficulties to interact with normal persons. The presented structure identifies the sign of the Arabic alphabet grounded on real-time user inputs. In Bilgin and Mutludoğan (2019), the detection of sign language characters using a structure that has been trained via images of letters in ASL is intended. Capsule networks, which can be projected in the recent period, were utilized for testing and training processes and likened with LeNet which can be the first successful and presently with a method of DL. Hossain et al. (2020) devised a method to identify Bangla sign language (BSL) gestures with CNN. A large amount of openly available sign language data have been utilized to find BSL.
In Selvanambi et al. (2023), different methods to forecast what a user can be irritated to convey over hand gestures with ASL. A chapter emphasizes the presented approach or tool that is leveraged for practices of ASL by regular persons to practice and learn sign language. Marzouk et al. (2022) intended an ASODCAE-SLR method, expanded as atom search optimization include deep convolution AE-enabled sign language detection, for hearing and speaking disabled persons. The presented approach targets to support the interaction of speaking and hearing disabled people through the SLR procedure. As well, the devised method uses CapsNet feature extractors to generate a set of feature vectors.
MATERIALS AND METHODS
In this study, we have aimed to develop an automated sign language recognition using the EBESO-TLSLR technique for hearing-impaired persons. The presented EBESO-TLSLR technique is intended to offer effective communication among hearing-impaired persons and normal persons using the DL models. In the EBESO-TLSLR technique, a three-stage process is derived namely SqueezeNet feature extraction, LSTM-based sign recognition, and EBESO-based parameter tuning. Figure 1 depicts the workflow of the EBESO-TLSLR approach.

Workflow of the EBESO-TLSLR approach. Abbreviation: EBESO-TLSLR, Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition.
Feature extraction process
In the EBESO-TLSLR technique, the SqueezeNet model is used for feature map generation. SqueezeNet model can be a DCNN, which has a small amount of parameters, compressed structure, and attained higher precision than ImageNet and AlexNet with a similar amount of parameters ( Thanki, 2023). The major advantages are easier to deploy on a cloud platform, can be used and customized on hardware with restricted memory, and has fewer communication channels for training. This original SqueezeNet consists of 14 layers namely 3 max-pooling layers, 8 fire layers, 2 conventional convolution layers, 1 softmax, and a global avg-pooling layer. In this model, the convolution layer is exploited for extracting features from the input color retinal imageries. This sequential method comprises of a convolution layer, ith standalone Conv layer, and eight fire components. The amount of filters per fire component is increased progressively. The max pooling having the stride of 2 is implemented afterwards layers Conv layer 2, Conv layer 1, fire 3, and fire 7. The fire model is a squeeze Conv layer which comprises a 1×1 size fed into the expanding layer that has a mix of 1×1 and 3×3 convolutional filters. There are three tunable hyperparameters namely s1×1, e1×1, and e3×3. The e1×1 and e3×3 are expanded layers with filter sizes of 1×1 and 3×3, correspondingly, while s1×1 is a squeeze layer with a filter size of 1×1. Here, a fire module with hyperparameter s1×1 is used to limit the amount of input channels to the 3×3 size. After extracting features from the input retinal images, the flattened layer is used to convert features into a 1D0 layer.
Recognition process using the optimal LSTM model
To recognize various sign language classes, the LSTM approach was used. LSTM is a special kind of RNN used in the domain of DL. The main factor of the LSTM method is to present a storage unit for cyclic data communication, which records every past data up to the present moment ( Wang et al., 2022). Thus, in comparison to the short-term memory of conventional RNN, LSTM with long-term memory abilities: a gating model (including forget, input, and output gates) with a value between [0, 1] can be used for controlling the communication path of the internal data in the method.
Where tanh denotes the activation function. c t− 1 and h t− 1 denote the output of the memory unit and hidden layer (HL) at t–1 time. c t , x t , it, f ta t h t , and o t characterize storage unit, input, forget, candidate state, input gate, the output of HL, and output gate at t time, correspondingly. δ shows the logistic sigmoid function. Figure 2 represents the infrastructure of LSTM.

The weights between HL and the output, forget, memory unit, and input gates, are represented as W ho , W hf , W hc , and W hi . W xo , W xf, W xi , and W xc correspondingly indicate the weight connection of the output gate, forget gate, input gate, and storage unit. ⊙ shows the product of vector components. b f , b i , and b o indicate the bias. The LSTM loop structure controls the data flow by controlling the degree of closing and opening of forget, input, and output gates. Steps 1 to 6 are given as follows:
Step1: The forget gate f t takes input x t of the existing layer and the output h t −1 of HL at the prior moment as input, and the resultant output of forget gate can be multiplied with c t −1 for controlling what amount of data should be forgotten in the internal state c t −1 at the prior moment.
Step2: The input gate stores the present input data and the resultant output is utilized as the data to be updated.
Step3: The output gate 0 fj controls internal state c fj at the present moment, for controlling what amount of data should be outputted to the external state h fj .
Step4: The output gate o t is multiplied by the state of the storage unit processed by the tanh function. The output h fj of HL is evaluated using Eq. (4):
Step5: The memory unit c fj records the prior data up to the present moment that is evaluated as follows:
Step6: The candidate state can be formulated as follows:
Finally, the EBESO algorithm is used for optimal hyperparameter tuning. Bald eagles often feast on protein-rich food. It targets fish ( Alsaidan et al., 2022). Bald eagle chooses a space between the deep water and the land surface. The search step begins after the hunter attains the specified region. As well, bald eagles have outstanding eyesight that allows them to mark the fish inside the water from a higher distance in the air. Once the hunter specifies its targets, it begins to slowly descend to grab the fish and to catch its victim. The mathematical representation and equation of the BESO algorithm label the three phases of hunting by the bald eagle.
The first stage (selection)
The bald eagle defines the region where it could capture the fish. This phase is shown in mathematical method as follows:
In Equation (7), α denotes the location change control parameter ϵ [1.5, 2]. r ϵ [ O, 1] at random. Another exploration region is chosen that is nearby to the formerly chosen one. P best is an existing exploration space defined by the bald eagles. It can be selected based on the previous location defined. P mean demonstrates that the eagle benefits from the data of the prior position. This initial phase significantly improves the candidate solution based on the mean location and the better location.
The second stage (search)
In this stage, the hunter searches for the victim. The search can be performed in the previously defined exploration region. Next, the eagle travels in different directions in the spiral region so that the searching process can be speeded up:
In Eq. (8), a denotes the random variables ϵ [5, 10]. ‘a’ and ‘R’ parameters control the variation in spiral shape. Likewise, the variable R ϵ [0.5, 2] controlled the determination of the exploration cycle number.
In this stage, the location moves toward the center. Once the ‘a’ and ‘R’ change, the BESO algorithm diversifies to seek more accurate solutions and to prevent trapping in the local solution.
The third stage (swooping)
In the hunting process, swooping is the third and last phase, where the eagles move from the better position toward the targeted prey.
From the expression, the two random parameters, c1 and c2, change between 1 and 2 to further intensify the motion of the hunting eagle toward the better position. The mean solution might push the presented method to diverse or intense toward the optimum solution.
Finally, the optimum solution is accomplished by a minimal amount of iterations. All the stages are affected by intensification and diversification factors. They are significant for the continual upgrade to the candidate solution and lastly, to obtain the optimum one.
In the EBESO algorithm, the levy function can be included for improving the outcome of the presented BES method. This can be performed by altering the search agent-utilizing factor “LF”. This factor is arithmetically evaluated using the following expression:
Where v and u denote random values within [0, 1].
In the third step, the Levy function is inserted, the Swoop step. The new population can be evaluated using Equation (11).
Where r 1 denotes a random integer within [0, 1]. P1 and CF are constants. The stepsize l is evaluated using Equation (12):
RESULTS AND DISCUSSION
The sign language detection and classification outcomes of the EBESO-TLSLR method are demonstrated.
In Table 1 and Figure 3, the overall sign language recognition results of the EBESO-TLSLR technique are illustrated. The experimental values suggest that the EBESO-TLSLR technique reaches improved recognition rates. For instance, with 70% of TRP, the EBESO-TLSLR technique obtains average accu y , prec n , reca l , and F score of 99.42, 99.30, 99.37, and 99.39%, respectively. On the other hand, with 30% of TSP, the EBESO-TLSLR method attains average accu y , prec n , reca l , and F score of 98.46, 98.55, 98.54, and 98.41%, correspondingly.

Average outcome of the EBESO-TLSLR approach on 70:30 of TRP/TSP. Abbreviation: EBESO-TLSLR, Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition.
Sign language recognition outcome of the EBESO-TLSLR system on 70:30 of TRP/TSP.
| Training phase (70%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Sign | Accu y | Prec n | Reca l | F score | Sign | Accu y | Prec n | Reca l | F score |
| A | 99.03 | 99.26 | 99.72 | 99.15 | P | 99.67 | 99.22 | 99.68 | 99.28 |
| B | 99.53 | 99.67 | 99.26 | 99.40 | Q | 99.44 | 99.05 | 99.31 | 99.20 |
| C | 99.60 | 99.59 | 99.72 | 99.51 | R | 99.41 | 99.25 | 99.64 | 99.51 |
| D | 99.31 | 99.45 | 99.00 | 99.65 | S | 99.71 | 99.37 | 99.09 | 99.09 |
| E | 99.56 | 99.08 | 99.74 | 99.23 | T | 99.14 | 99.57 | 99.07 | 99.23 |
| F | 99.31 | 99.05 | 99.27 | 99.30 | U | 99.34 | 99.45 | 99.24 | 99.77 |
| G | 99.00 | 99.06 | 99.50 | 99.53 | V | 99.65 | 99.43 | 99.22 | 99.62 |
| H | 99.28 | 99.10 | 99.10 | 99.79 | W | 99.57 | 99.30 | 99.71 | 99.07 |
| I | 99.71 | 99.26 | 99.62 | 99.79 | X | 99.38 | 99.73 | 99.79 | 99.40 |
| J | 99.57 | 99.24 | 99.03 | 99.10 | Y | 99.74 | 99.68 | 99.07 | 99.54 |
| K | 99.24 | 99.13 | 99.16 | 99.13 | Z | 99.28 | 99.72 | 99.04 | 99.79 |
| L | 99.54 | 99.72 | 99.36 | 99.55 | Space | 99.30 | 99.55 | 99.08 | 99.59 |
| M | 99.42 | 99.48 | 99.01 | 99.28 | Nothing | 99.53 | 99.25 | 99.48 | 99.64 |
| N | 99.65 | 99.06 | 99.27 | 99.06 | Delete | 99.44 | 99.34 | 99.30 | 99.28 |
| O | 99.51 | 99.31 | 99.73 | 99.42 | Average | 99.42 | 99.30 | 99.37 | 99.39 |
| Testing phase (30%) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Sign | Accu y | Prec n | Reca l | F score | Sign | Accu y | Prec n | Reca l | F score |
| A | 98.43 | 98.49 | 98.49 | 98.76 | P | 98.54 | 98.79 | 98.19 | 98.68 |
| B | 98.66 | 98.46 | 98.61 | 98.29 | Q | 98.72 | 98.18 | 98.13 | 98.39 |
| C | 98.14 | 98.38 | 98.71 | 98.51 | R | 98.85 | 98.35 | 98.08 | 98.51 |
| D | 98.58 | 98.68 | 98.58 | 98.24 | S | 98.70 | 98.32 | 98.91 | 98.31 |
| E | 98.62 | 98.56 | 98.13 | 98.48 | T | 98.51 | 98.45 | 98.52 | 98.65 |
| F | 98.07 | 98.26 | 98.04 | 98.52 | U | 98.96 | 98.56 | 98.85 | 98.68 |
| G | 98.29 | 98.59 | 98.21 | 98.15 | V | 98.01 | 98.80 | 98.60 | 98.65 |
| H | 98.25 | 98.44 | 98.79 | 98.54 | W | 98.57 | 98.61 | 98.53 | 98.40 |
| I | 98.46 | 98.15 | 98.71 | 98.87 | X | 98.60 | 98.03 | 98.12 | 98.59 |
| J | 98.14 | 98.61 | 98.42 | 98.66 | Y | 98.63 | 98.88 | 98.18 | 98.09 |
| K | 98.75 | 98.97 | 98.08 | 98.05 | Z | 98.43 | 98.80 | 98.79 | 98.67 |
| L | 98.93 | 98.87 | 98.94 | 98.79 | Space | 99.00 | 98.44 | 98.02 | 98.20 |
| M | 98.53 | 98.90 | 98.82 | 98.05 | Nothing | 98.56 | 98.51 | 98.89 | 98.61 |
| N | 98.60 | 98.70 | 98.95 | 98.14 | Delete | 98.75 | 98.81 | 98.19 | 98.60 |
| O | 98.44 | 98.21 | 98.57 | 98.17 | Average | 98.46 | 98.55 | 98.54 | 98.41 |
Abbreviation: EBESO-TLSLR, Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition.
Figure 4 inspects the accuracy of the EBESO-TLSLR method in the training and validation of the test database. The result specified that the EBESO-TLSLR technique reach higher accuracy values over greater epochs. Also, the higher validation accuracy over training accuracy portrayed that the EBESO-TLSLR technique learns productively on the test database.

Accuracy curve of the EBESO-TLSLR approach. Abbreviation: EBESO-TLSLR, Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition.
The loss analysis of the EBESO-TLSLR technique in the training and validation is given on the test database in Figure 5. The result points out that the EBESO-TLSLR method reaches closer values of training and validation loss. The EBESO-TLSLR method learns productively on a test database.
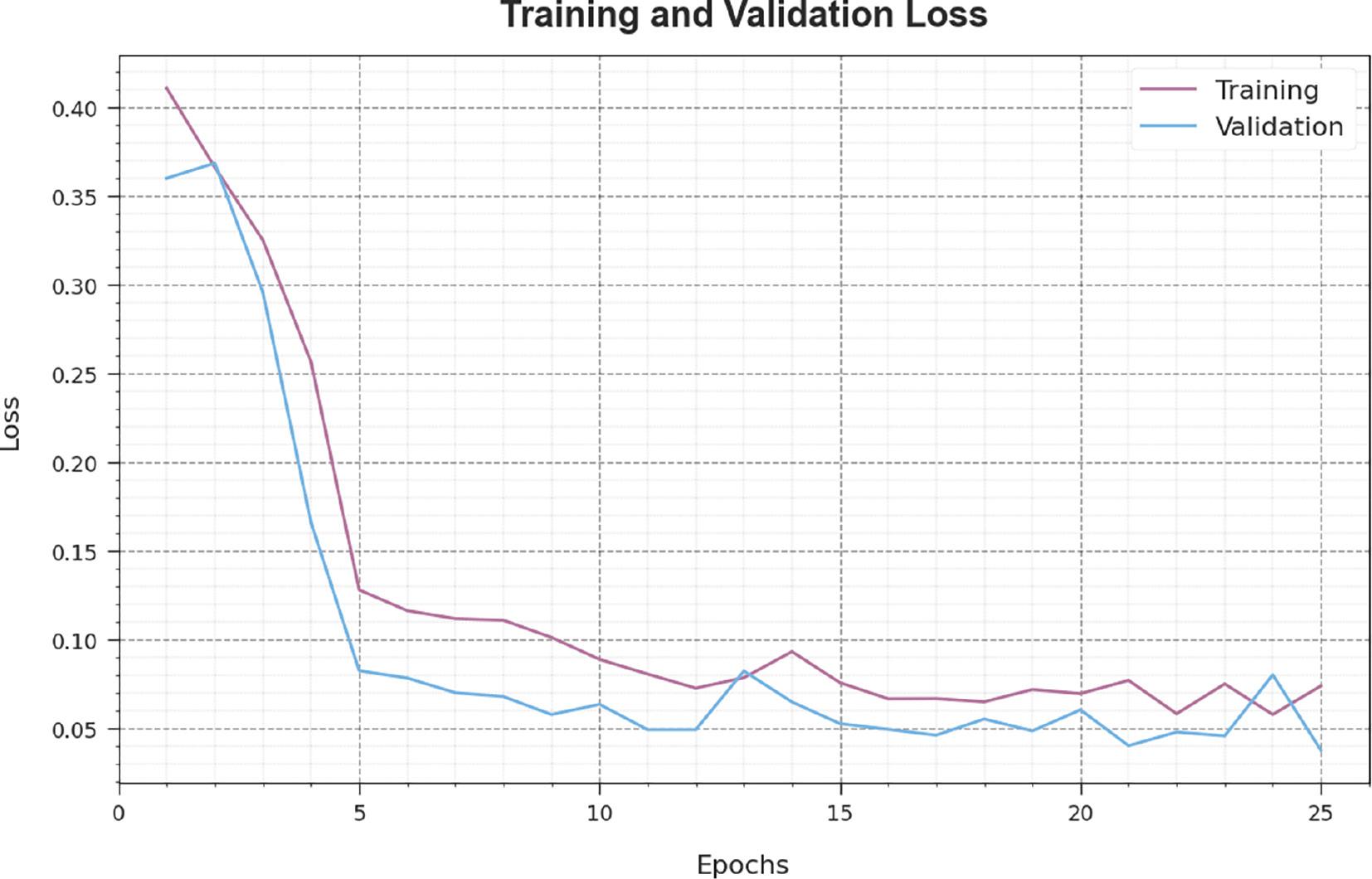
Loss curve of the EBESO-TLSLR approach. Abbreviation: EBESO-TLSLR, Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition.
In Table 2, a detailed comparison study of the EBESO-TLSLR method is reported with recent approaches ( Alrowais et al., 2022).
Comparative outcome of the EBESO-TLSLR approach with other methods.
| Methods | Accuracy (%) | Computation time (minutes) |
|---|---|---|
| KNN algorithm | 96.25 | 16.54 |
| SVM model | 98.10 | 14.34 |
| ANN model | 98.11 | 15.41 |
| CNN model | 99.09 | 11.21 |
| ODTL-SLRC | 99.03 | 06.44 |
| EBESO-TLSLR | 99.42 | 03.01 |
Abbreviation: EBESO-TLSLR, Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition.
Figure 6 illustrates the accu y investigation of the EBESO-TLSLR method with existing techniques. The result demonstrates that the EBESO-TLSLR technique reaches improved performance. Based on accu y , the EBESO-TLSLR technique obtains accu y of 99.42% while the existing KNN, SVM, ANN, CNN, and ODTL-SLRC techniques attained accu y of 96.25, 98.10, 98.11, 99.09, and 99.03%, correspondingly.

Accu y outcome of the EBESO-TLSLR approach with other approaches. Abbreviation: EBESO-TLSLR, Enhanced Bald Eagle Search Optimizer with Transfer Learning Sign Language Recognition.
Figure 7 illustrates the CT investigation of the EBESO-TLSLR method with existing approaches. The result highlighted that the EBESO-TLSLR method reaches improved performance. Based on CT, the EBESO-TLSLR approach gains CT of 3.01 m while the existing KNN, SVM, ANN, CNN, and ODTL-SLRC algorithms attained CT of 16.54, 14.34, 15.41, 11.21, and 6.44 m correspondingly. These outcomes reassured the better performance of the EBESO-TLSLR method over other approaches.

CONCLUSION
In this study, we have aimed to develop automated sign language recognition using the EBESO-TLSLR technique for hearing-impaired persons. The presented EBESO-TLSLR technique is intended to offer effective communication among hearing-impaired persons and normal persons using the DL models. In the EBESO-TLSLR technique, the SqueezeNet model is used for feature map generation. For recognition of sign language classes, the LSTM method is used. Finally, the EBESO method is exploited for the optimal hyperparameter election of the LSTM model. The simulation results of the EBESO-TLSLR approach are validated on the sign language dataset. The simulation outcomes illustrate the superior results of the EBESO-TLSLR technique with a maximum accuracy of 96.25%. In future, the detection rate of the EBESO-TLSLR method can be boosted by the feature fusion process.