
INTRODUCTION
A disability is one of the big concerns that continues to cause difficulties. Disability remains a source of frustration; meanwhile, it is viewed as a limitation, a cognitive handicap, mental and physical, that limits the individual’s growth and involvement ( Venkit and Wilson, 2021). Consequently, excessive efforts are given in eradicating this type of restriction. People with disabilities should depend on others to meet their necessities ( Hutchinson et al., 2020). Machine learning (ML) constructs smart cities and presents a secure existence for handicapped individuals. Artificial Intelligence (AI) is the part of computer science that concentrates on devising smart computer mechanisms that show traits related to human intelligence, such as decision-making, comprehending languages, learning problem solving, etc. ( Tembhurne and Diwan, 2021). One main contribution of AI has continued in Natural Language Processing (NLP) joined computational and linguistic approaches to support computers in facilitating human–computer interaction and understanding human languages ( Gavidia et al., 2022). Text summarization, speech recognition, conversational or agents chatbots, sentiment analysis (SA), and machine translation fall under the research areas in the domain of NLP ( Lingiardi et al., 2020).
Emotions are characterized into six types: anger, joy, fear, surprise, disgust, and sadness. Furthermore, emotion is labeled in different forms, namely love, hopefulness, etc. Speech, facial expressions, text, and gestures express the emotions and moods of humans ( Tarvainen, 2021). Different from speech recognition and facial expression, a text sentence loses the capability to describe itself since it is tasteless ( Stankevich et al., 2019). Due to the ambiguity and complexity of the text, it seems to be hard task to identify the emotions in that text. It is a problematic task to ascertain the emotion of given text as all words can have a diverse morphological form and meaning ( Geiger et al., 2020). Currently, scholars have developed diverse approaches to determine text emotions, like learning-based, keyword-based, hybrid, and lexical affinity methods. In the opening, they presented a rule-related method that has two methods, like, keyword based and lexical affinity based ( Wegner, 2020). Afterwards, a novel algorithm came into existence which is the learning-related method. This method has higher level of accuracy and brings better outcomes. In a learning-related method, various approaches can be leveraged for finding emotions ( Abdollahi et al., 2022). Many authors have combined the methods and made them hybrid in the search for more precision. The study stated that DL approaches have superior precision compared to ML approaches for large amounts of data or text. But for small datasets, ML presents us with superior precision.
Ombabi et al. (2020) devised a new DL approach for Arabic language SA related to one layer CNN model for extracting local features, and two layers of LSTM for upholding long-term dependency. The feature map learned through LSTM and CNN is sent to the SVM method for generating the concluding classification. This FastText words embedding method supports this method. Venkit and Wilson (2021) have addressed the discrimination against persons with disability, PWD, performed by SA, and toxicity classifier methods. The authors offer an inspection of sentiments and toxicity analysis approaches to comprehend briefly how they distinguish PWD. The authors introduced the BITS, a corpus of 1126 sentences devised to probe SA approaches for biases in disabilities.
Bashir et al. (2022) devised an openly accessible Urdu Nastalique Emotions Dataset (UNED) of sentences and paragraphs annotated with diverse emotions and offered a DL-related method to classify emotion in the UNED corpus. The presented method has six emotions for sentences and paragraphs. The author performed wide-ranging experiments to assess the quality of corpus and categorize it with DL and ML methodologies. AlZu’bi et al. (2022) develop a DL approach for finding the emotions of students. The study aims to map the relationship between teaching practices and student learning related to emotional effects. Facial method approaches abstract useful data from online platforms as image classifier methods are adopted to find the emotions of teacher or student faces. The two DL methods are compared as per their performance.
Qiu et al. (2022) propose a new sentimental index to forecast the stock trends related to the weighted textual content and financial anomaly. To be specific, the authors first devised a new weighting technique to weight all stock reviews. Next, the holiday and day-of-the-week effects are considered for building dependable and realistic modified sentiment index. Alsayat (2022) focused on improving the performance of sentiment classification with the use of a customized DL approach with an advanced word embedding method and constructing an LSTM network. Besides, the author devised an ensemble approach that combined baseline classifier with other classifiers utilized for SA.
This study introduces a new salp swarm algorithm with deep recurrent neural network-based textual emotion analysis (SSADRNN-TEA) technique for disabled persons. The major intention of the SSADRNN-TEA technique was to focus on the detection and classification of emotions that exist in social media content. In this work, the SSADRNN-TEA technique undergoes preprocessing to make the input data compatible with the latter stages of processing and BERT word embedding process is applied. Moreover, the deep recurrent neural network (DRNN) model is exploited. Finally, SSA is exploited for the optimum adjustment of the DRNN hyperparameters. A widespread experiment is involved in simulating the real-time performance of the SSADRNN-TEA method.
THE PROPOSED TEXTUAL EMOTION ANALYSIS MODEL
In this study, a novel SSADRNN-TEA technique was devised for disabled persons. The major intention of the SSADRNN-TEA technique was to focus on the detection and classification of emotions that exist in social media content. In this work, the SSADRNN-TEA technique undergoes three major stages, namely, data preprocessing, DRNN-based emotion detection, and SSA-based parameter tuning. Figure 1 defines the overall process of the SSADRNN-TEA approach.
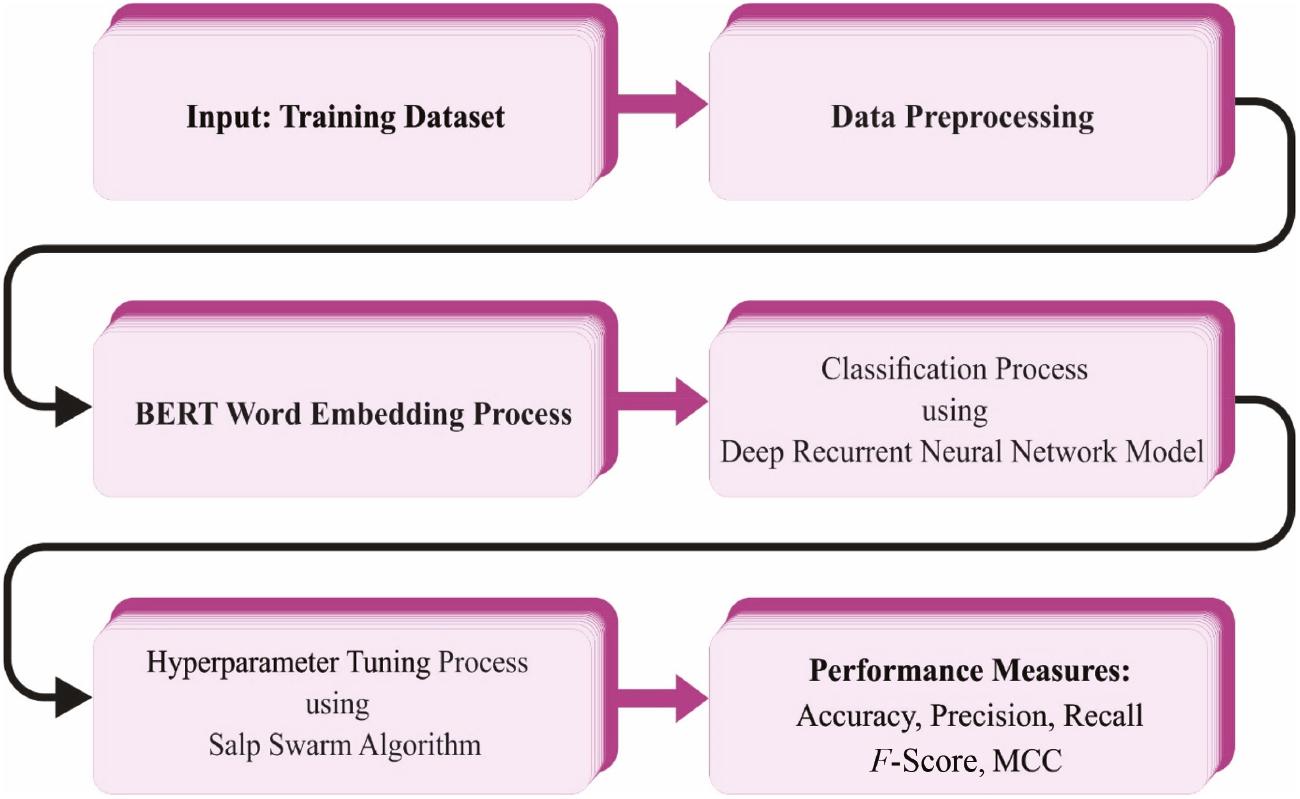
Overall procedure of the SSADRNN-TEA method. Abbreviation: SSADRNN-TEA, salp swarm algorithm with deep recurrent neural network-based textual emotion analysis.
Stage I: Data preprocessing
In this work, the SSADRNN-TEA technique undergoes preprocessing to make the input data compatible with the latter stages of processing and BERT word embedding process is applied ( Qorib et al., 2023). Before performing text sentiment classification, text preprocessing is vital in the NLP model. In this stage, text was prepared to be trainable for ML approaches. The initial stage is the removal of retweets. A retweet is a tweet shared by other users. This might lead to tweet duplication. Removal of retweets might normalize the data. Further advantage of eliminating retweets is to minimalize the space needed for running the experiment. Accordingly, to enhance the classification models we removed retweets.
The next step is to eliminate URL and punctuation. It can be vital to clean the URL because every tweet has a link. Moreover, punctuation will eliminate unnecessary items and remove nonuseful signs from the database. Since punctuations and URLs have no meaning, eliminating unwanted items might enhance efficacy of the model.
Then, emojis are converted into words. The library emoji.demojize () is used for converting emojis into words. Converting emojis into words might enhance SA of the tweets’.
Later, tokenization and normalization were performed. Tokenization is a way to split words in all the tweets; hence, it is useful for performing text-based SA. Normalization is a way of normalizing the group of words by lower case as normalization word. Before computing its polarity, all the words in tweets are saved in a group of words.
The stop words are removed from the collection of words after normalizing phrases. In this analysis, Removing English stop words, namely, ‘is’, ‘am’, ‘hasn’t’, ‘aren’t’, and so on, is useful in calculating text-based SA as these stop words are not valuable. Accordingly eliminating them might enhance text-based SA.
The next stage was lemmatization and stemming. Stemming is a way of converting words as root or base form. Words like learned, learning, or learns are converted to learn. Decreasing the word form to the base form might normalize the word structure. In this experiment, we used PorterStemmer.
Stage II: Emotion detection using the DRNN model
Here, the DRNN model is exploited. Perception and Learning are intrinsic to RNN meanwhile RNN is composed of ANN ( Venugopal et al., 2023). Amending the weight and bias of interlayer relations among the neurons so that it can be learned. Node characterizes normalized condition recovered from intended error is added from the input layer. The hidden and output layers are utilized in sigmoid activation function. In such cases, the RNN was tested, designed, and implemented by MATLAB or Simulink environments.
Step1: The input vector ω is employed in the input layer. The RNN input is error deviation E r ( t) and error e r ( t),
The j th hidden units of the net input are provided as follows:
Step2: The resultant of neuron in the HL is described as follows:
With these changes, the net input to resultant layer neuron is as follows:
Step3: Lastly the yield of neurons, viz., the current outcome of the feed-forward loop P act from the resultant layer.
Step4: A gradient-descent method with the BP method is exploited to the weight and bias to minimize performance of MSA. The input of RNN is the error e r ( t) and the error deviation E r ( t) as
Step5: The upgrading expression and the matching synaptic weight are given below.
Stage III: SSA-based parameter tuning
Finally, SSA is exploited for the optimum adjustment of the DRNN hyperparameters. The SSA technique inspires the lifestyle of salp swarm population, and the main goal is to arbitrarily search for a sufficient solution space and determine better or estimated solutions. The salp population has been separated into two groups namely followers and leaders ( Wei et al., 2023). The place of salps is determined in the n-dimensional searching space, in which n states to the count of variables to provide problem. During this SSA, a primary population was arbitrarily created. The searching space is fixed as N × n dimensions.
This technique creates a primary population with the subsequent equation, defined mathematically in Eq. (10).
where ub and lb refer to the upper and lower boundaries, correspondingly. The leader variations with the place of food sources, upgraded based on Eq. (11).
Particularly, F j stands for the food source place, x1j implies the leader’s position, and c 2 and c 3 represent both random on 0 and 1. C 2 signifies the leader moving speed, c 3 indicates the negative and positive directions of leader movements, and the parameter c 1 denotes the time variable co-efficient. The c 1 is calculated using (12).
In which, t signifies the iteration number, and T max defines the fixed maximal which is specified. The position of followers is upgraded dependent upon the location of leaders, with concern for the location of previous person. Utilizing Newton’s law of motion formula, the followers can be upgraded based on Eq. (13).
where xij stands for the follower place and xi−1j implies the position of the preceding follower. Figure 2 demonstrates the flowchart of SSA.

The SSA system not only develops an FF to conquer superior classier accuracy and defines a positive integer to illustrate the best efficacy of candidate results. The decline of the classification error rate is supposed that FF, as follows:
RESULT ANALYSIS
In this section, the emotion identification result of the SSADRNN-TEA technique is examined on an emotion detection dataset. It has 3500 samples with seven classes as demonstrated in Table 1.
Details of the database.
| Class | No. of instances |
|---|---|
| Fear | 500 |
| Joy | 500 |
| Anger | 500 |
| Sad | 500 |
| Disgust | 500 |
| Guilt | 500 |
| Shame | 500 |
| Total number of samples | 3500 |
Figure 3 demonstrates the classifier grades of the SSADRNN-TEA method under test dataset. Figure 3a and b depicts the confusion matrix offered by the SSADRNN-TEA approach on 80:20 of TRP/TSP. The result implied that the SSADRNN-TEA method has recognized and classified all seven class labels accurately. Likewise, Figure 3c exemplifies the PR investigation of the SSADRNN-TEA model. The figures described that the SSADRNN-TEA method has obtained maximum PR performance under seven classes. Lastly, Figure 3d demonstrates the ROC investigation of the SSADRNN-TEA method. The result depicted that the SSADRNN-TEA approach has led to proficient outcomes with maximal ROC values on seven classes.
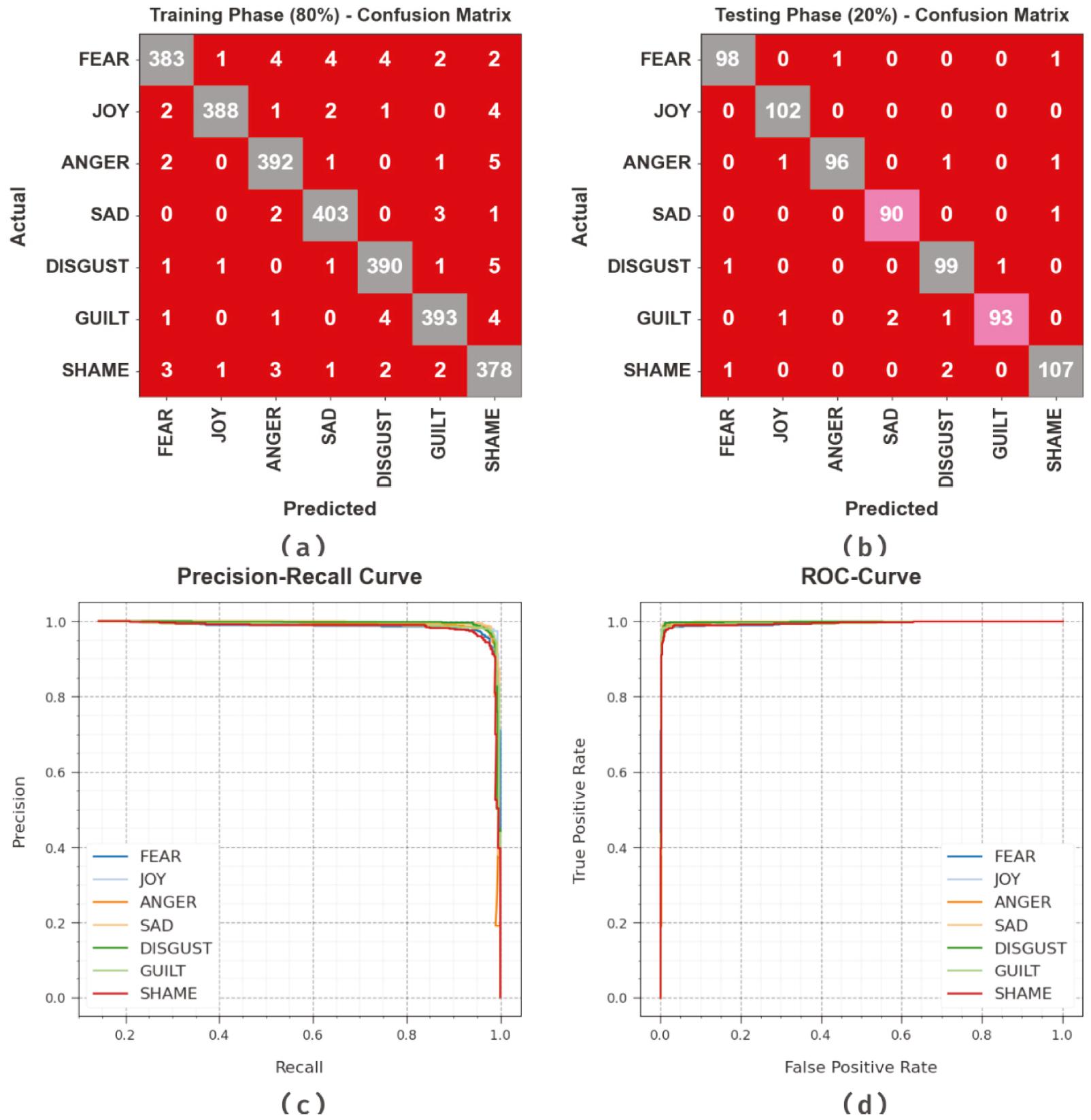
Classifier outcome of the SSADRNN-TEA system: (a,b) Confusion matrices, (c) PR-curve, and (d) ROC-curve. Abbreviation: SSADRNN-TEA, salp swarm algorithm with deep recurrent neural network-based textual emotion analysis.
In Table 2, a widespread emotion recognition result of the SSADRNN-TEA technique is depicted. The results indicate the improvement of the SSADRNN-TEA technique under all kinds of emotions. For instance, on 80% of TRP, the SSADRNN-TEA technique obtains average accu y, prec n, reca l, F score, and MCC of 99.26, 97.40, 97.39, 97.39, and 96.96%, respectively. Eventually, on 20% of TSP, the SSADRNN-TEA technique obtains average accu y, prec n, reca l, F score, and MCC of 99.39, 97.89, 97.86, 97.87, and 97.51%, correspondingly.
Emotion recognition outcome of the SSADRNN-TEA method on 80:20 of TRP/TSP.
| Class | Accu y | Prec n | Reca l | F score | MCC |
|---|---|---|---|---|---|
| Training phase (80%) | |||||
| Fear | 99.07 | 97.70 | 95.75 | 96.72 | 96.18 |
| Joy | 99.54 | 99.23 | 97.49 | 98.35 | 98.09 |
| Anger | 99.29 | 97.27 | 97.76 | 97.51 | 97.10 |
| Sad | 99.46 | 97.82 | 98.53 | 98.17 | 97.86 |
| Disgust | 99.29 | 97.26 | 97.74 | 97.50 | 97.08 |
| Guilt | 99.32 | 97.76 | 97.52 | 97.64 | 97.24 |
| Shame | 98.82 | 94.74 | 96.92 | 95.82 | 95.14 |
| Average | 99.26 | 97.40 | 97.39 | 97.39 | 96.96 |
| Testing Phase (20%) | |||||
| Fear | 99.43 | 98.00 | 98.00 | 98.00 | 97.67 |
| Joy | 99.71 | 98.08 | 100.00 | 99.03 | 98.87 |
| Anger | 99.43 | 98.97 | 96.97 | 97.96 | 97.63 |
| Sad | 99.57 | 97.83 | 98.90 | 98.36 | 98.12 |
| Disgust | 99.14 | 96.12 | 98.02 | 97.06 | 96.56 |
| Guilt | 99.29 | 98.94 | 95.88 | 97.38 | 96.98 |
| Shame | 99.14 | 97.27 | 97.27 | 97.27 | 96.76 |
| Average | 99.39 | 97.89 | 97.86 | 97.87 | 97.51 |
Abbreviation: SSADRNN-TEA, salp swarm algorithm with deep recurrent neural network-based textual emotion analysis.
Figure 4 inspects the accuracy of the SSADRNN-TEA method during the training and validation process on test database. The figure shows that the SSADRNN-TEA technique obtains maximum accuracy values over increasing epochs. Moreover, the higher validation accuracy over training accuracy shows that the SSADRNN-TEA method learns effectively on test database.
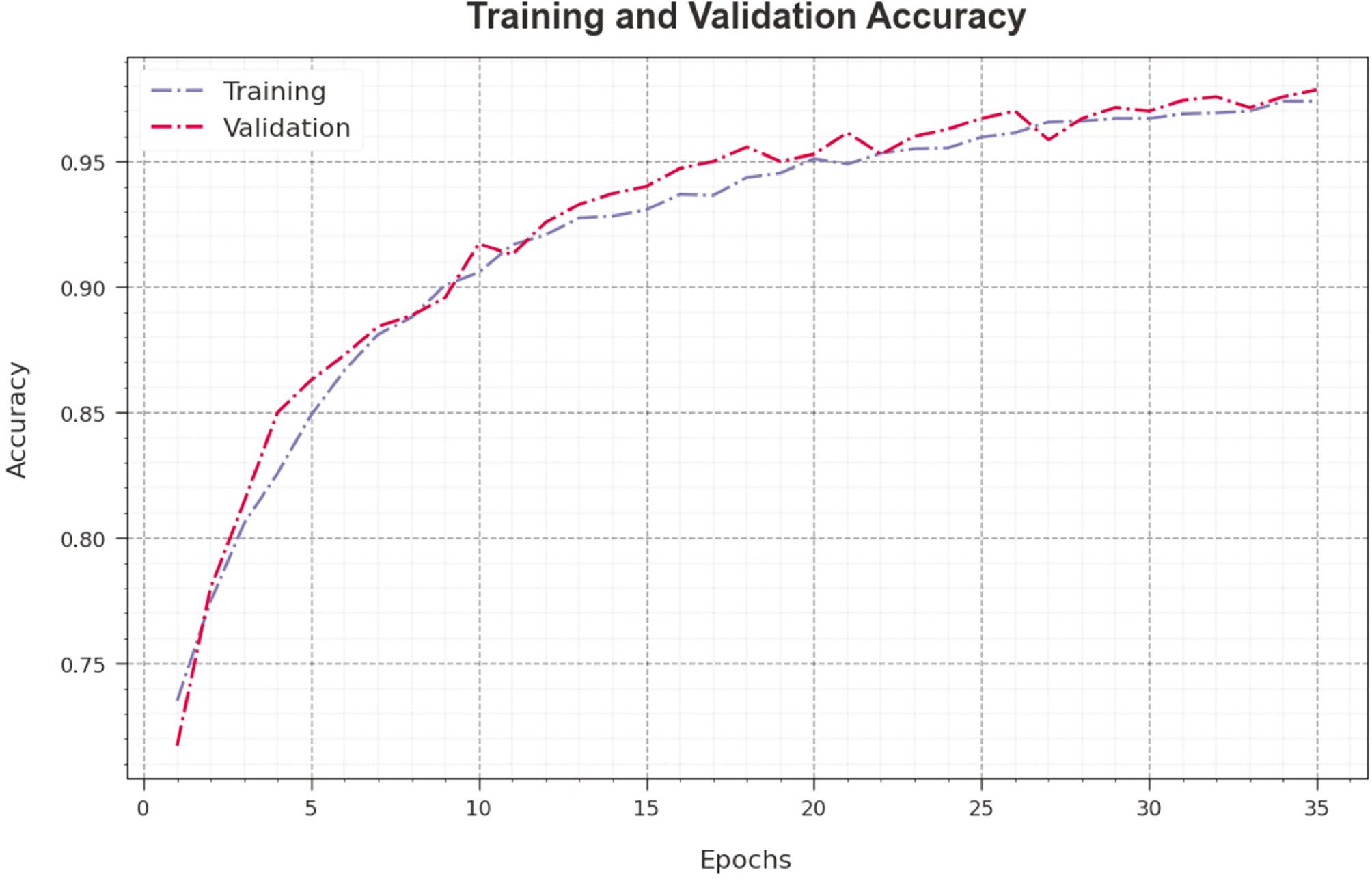
Accuracy curve of the SSADRNN-TEA approach. Abbreviation: SSADRNN-TEA, salp swarm algorithm with deep recurrent neural network-based textual emotion analysis.
The loss analysis of the SSADRNN-TEA technique at the time of training and validation is illustrated on test database in Figure 5. The results indicate that the SSADRNN-TEA technique obtains closer values of training and validation loss. It could be clear that the SSADRNN-TEA method learns effectively on test database.
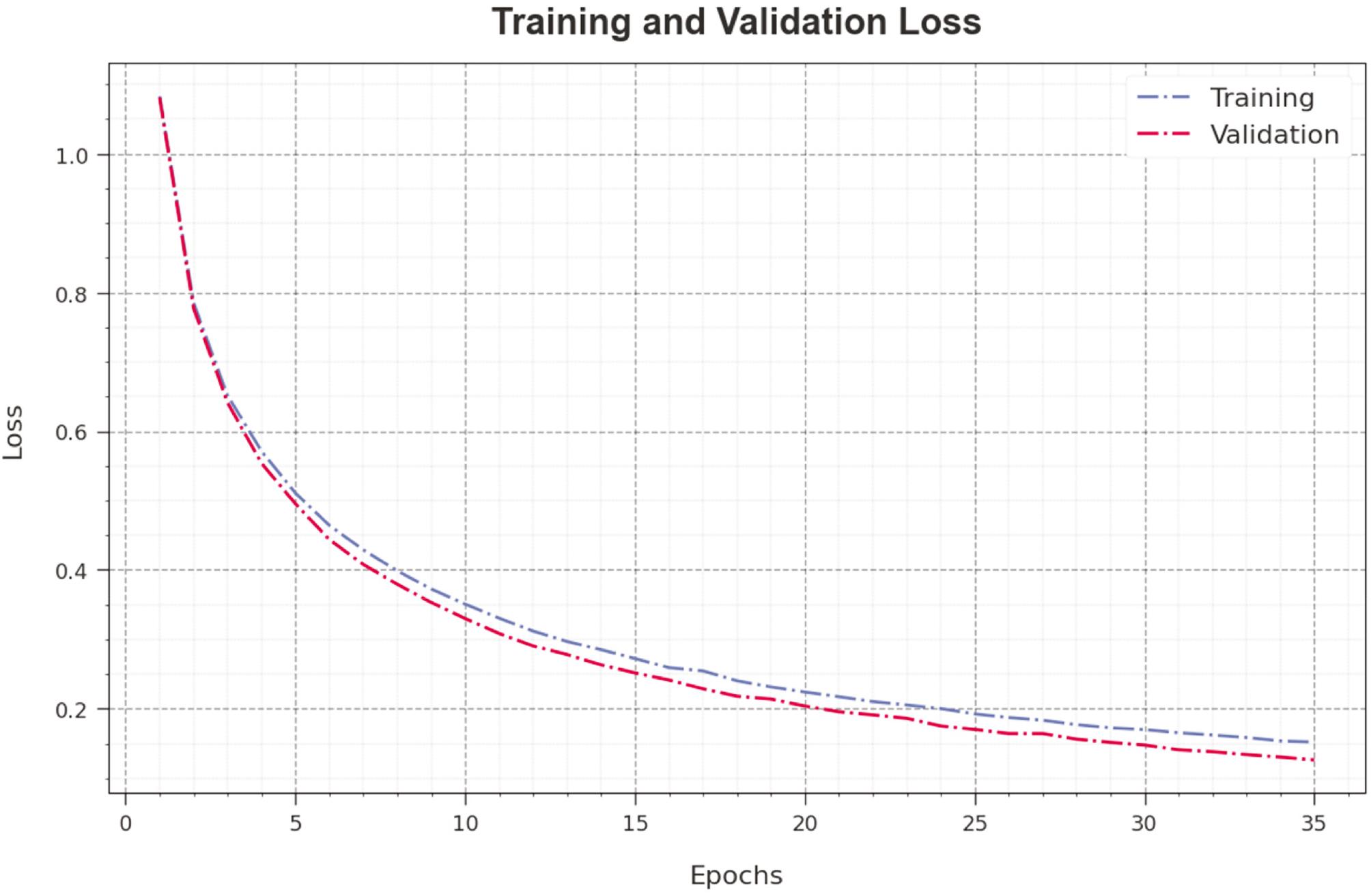
Loss curve of the SSADRNN-TEA approach. Abbreviation: SSADRNN-TEA, salp swarm algorithm with deep recurrent neural network-based textual emotion analysis.
The experimental emotion detection outcomes of the SSADRNN-TEA system are compared with other methods in Table 3 and Figure 6 ( Al-Baity et al., 2022). With respect to accu y , the SSADRNN-TEA technique highlights an increasing value of 99.39% while the CLBEDC-SND, LRA-DNN, DNN, CNN, and ANN models pointed out decreasing values of 98.72, 94.48, 92.08, 89.93, and 88.05%, respectively. Also, with respect to prec n , the SSADRNN-TEA method highlights an increasing value of 97.89% whereas the CLBEDC-SND, LRA-DNN, DNN, CNN, and ANN models pointed out decreasing values of 95.49, 87.96, 86.74, 80.47, and 78.43%, correspondingly. At the same time, with respect to reca l , the SSADRNN-TEA method highlights an increasing value of 97.86% while the CLBEDC-SND, LRA-DNN, DNN, CNN, and ANN methods pointed out decreasing values of 95.53, 91.7, 90.53, 87.59, and 84.75%, correspondingly. Finally, with respect to F score , the SSADRNN-TEA method highlights an increasing value of 97.87% whereas the CLBEDC-SND, LRA-DNN, DNN, CNN, and ANN models pointed out decreasing values of 96.25, 91.67, 88.39, 86.1, and 83.93%, correspondingly.
Comparative outcome of the SSADRNN-TEA method with other algorithms.
| Methods | Accu y | Prec n | Reca l | F score |
|---|---|---|---|---|
| SSADRNN-TEA | 99.39 | 97.89 | 97.86 | 97.87 |
| CLBEDC-SND | 98.72 | 95.49 | 95.53 | 96.25 |
| LRA-DNN | 94.48 | 87.96 | 91.7 | 91.67 |
| DNN | 92.08 | 86.74 | 90.53 | 88.39 |
| CNN | 89.93 | 80.47 | 87.59 | 86.1 |
| ANN | 88.05 | 78.43 | 84.75 | 83.93 |
Abbreviation: SSADRNN-TEA, salp swarm algorithm with deep recurrent neural network-based textual emotion analysis.

CONCLUSION
In this manuscript, we have devised a novel SSADRNN-TEA method for disabled persons. The major intention of the SSADRNN-TEA technique was to focus on the detection and classification of emotions that exist in social media content. In this work, the SSADRNN-TEA technique undergoes preprocessing to make the input data compatible with the latter stages of processing and BERT word embedding process is applied. In addition, the DRNN model is exploited. Finally, SSA is exploited for the optimal adjustment of the DRNN hyperparameters. A widespread experiment is involved in simulating the real-time performance of the SSADRNN-TEA method. The experimental values stated the greater performance of the SSADRNN-TEA system in terms of several evaluation metrics.